Skaitmeninės gerovės naršyklės pratęsimas
Įvadas
Šiandienos hiperareguojamame skaitmeniniame kraštovaizdyje vis sunkiau palaikyti sveikus ryšius su technologijomis. Nuolatiniai pranešimai, nesibaigiantys turinio srautai ir priklausomybę sukeliantys projektavimo modeliai gali sukelti skaitmeninį nuovargį, sumažinti produktyvumą ir net psichinės sveikatos iššūkius.
Siekdama išspręsti šias problemas, „Clarity Pro“ komanda sukūrė novatorišką naršyklės pratęsimą, kuriame naudojami elgesio psichologijos principai, siekdama konstruktyviai sutrikdyti kenksmingus skaitmeninius modelius. Užuot naudojantis agresyviu blokavimo ar ribojančiu laiko apribojimais, „Clarity Pro“ siūlo švelnias, kontekstas suvokiančias intervencijas, kurios palaipsniui nukreipia vartotojus į labiau apgalvotus skaitmeninius įpročius.
Šiame techniniame giluminiame nardyme mes ištirsime architektūrą, algoritmus ir diegimo detales, skirtas „Clarity Pro“ intelektualiam sutrikimo varikliui. Aptarsime iššūkius, su kuriais susiduria komanda, jų sukurti sprendimai ir geriausia praktika, kurią jie sekė, kad sukurtų tvirtą, keičiamą ir patogų vartotojui pritaikytą įrankį skaitmeninei gerovei.
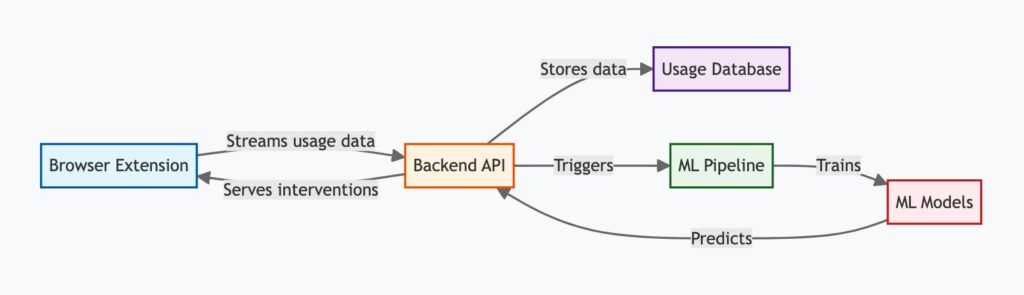
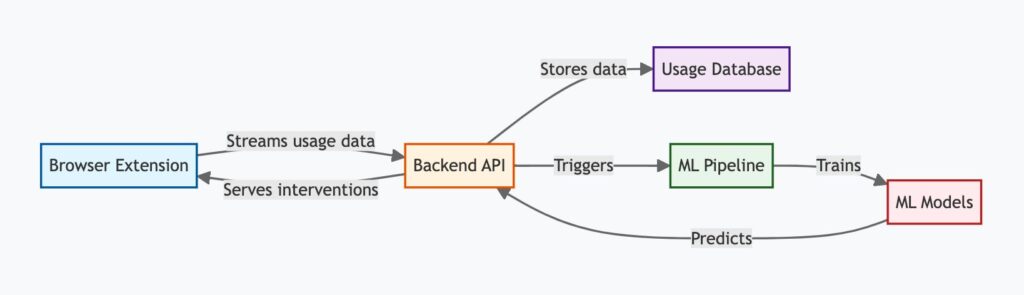
Sistemos architektūros apžvalga
„Clarity Pro“ susideda iš trijų pagrindinių komponentų:
- Naršyklės plėtinys: Vartotojo sąsaja, integruota su vartotojo žiniatinklio naršykle, seka naudojimo modelius ir pateikia kontekstines intervencijas.
- „Backend“ API: Be serverio, įvykių pagrindinė bazė, kuri apdoroja naudojimo duomenis, sukuria įžvalgas ir valdo vartotojo nuostatas.
- Mašinų mokymosi modeliai: ML modelių rinkinys, išmokytas naudoti vartotojo elgesio duomenis, kad būtų galima numatyti optimalų intervencijos laiką ir turinį.
Naršyklės plėtinio įgyvendinimas
„Clarity Pro“ naršyklės plėtinys sukurtas naudojant „TypeScript“ ir „React“, pasinaudojant „Webextensions“ API, kad būtų galima suderinti kryžminius naršykles. Pailginimą sudaro keli pagrindiniai moduliai:
1. Veiklos stebėjimo priemonė
ActivityTracker Modulis yra atsakingas už vartotojo veiklos duomenų fiksavimą, pavyzdžiui::
- Aktyvus skirtuko URL ir pavadinimas
- Slinkties pozicija ir sąveikos įvykiai
- Klaviatūra ir pelės veikla
- Skirtuko perjungimo dažnis
Čia yra supaprastinta veiklos stebėjimo logikos versija:
class ActivityTracker {
private readonly ACTIVITY_THRESHOLD = 5_000; // 5 seconds
private tabActivity: Map<number, TabActivity> = new Map();
constructor() {
browser.tabs.onActivated.addListener(this.handleTabActivated);
browser.tabs.onUpdated.addListener(this.handleTabUpdated);
browser.idle.onStateChanged.addListener(this.handleIdleStateChanged);
}
private async handleTabActivated({ tabId }: { tabId: number }) {
const tab = await browser.tabs.get(tabId);
this.tabActivity.set(tabId, this.createTabActivity(tab));
}
private handleTabUpdated(
tabId: number,
changeInfo: { url?: string },
tab: browser.tabs.Tab
) {
if (changeInfo.url) {
this.tabActivity.set(tabId, this.createTabActivity(tab));
}
}
private handleIdleStateChanged(newState: browser.idle.IdleState) {
if (newState === 'active') {
this.tabActivity.forEach((activity, tabId) => {
activity.idleTime = 0;
this.tabActivity.set(tabId, activity);
});
}
}
private createTabActivity(tab: browser.tabs.Tab): TabActivity {
return {
url: tab.url,
title: tab.title,
startTime: Date.now(),
scrollPosition: 0,
idleTime: 0,
// ... other activity metrics
};
}
// ... methods to track scroll, interaction, and idle time
} ActivityTracker klauso įvairių naršyklės įvykių, tokių kaip skirtukų aktyvinimas, URL pakeitimai ir tuščiosios eigos būsena, ir palaiko a tabActivity Žemėlapis, kad būtų saugomi dabartiniai kiekvieno skirtuko veiklos duomenys.
2. Intervencijos variklis
InterventionEngine Modulis nustato, kada ir kaip pateikti sąmoningus sutrikimus, atsižvelgiant į dabartinę vartotojo veiklą ir įžvalgas, kurias sukuria „Backend ML“ modeliai. Tai apibrėžia išplėtimą Intervention Sąsaja ir pateikia integruotos intervencijos tipų rinkinį, pavyzdžiui::
- Kvėpavimo pratimai
- Sąmoningas apmąstymų raginimas
- Kontekstinio turinio rekomendacijos
- Laipsniški UX pakeitimai (pvz., Lėtinantis puslapio įkėlimo laikas)
Štai pavyzdys Intervention Sąsaja ir paprasta kvėpavimo pratimų intervencija:
interface Intervention {
id: string;
type: InterventionType;
shouldTrigger: (activity: TabActivity, insights: Insights) => boolean;
render: () => void;
}
class BreathingExercise implements Intervention {
id = 'breathing_exercise';
type = InterventionType.Overlay;
shouldTrigger(activity: TabActivity, insights: Insights): boolean {
return (
activity.idleTime > 30_000 && // 30 seconds of idle time
insights.stressLevel > 0.7 // high predicted stress level
);
}
render() {
const overlayElement = document.createElement('div');
overlayElement.innerHTML = `
<div class="breathing-exercise">
<h2>Take a mindful breath</h2>
<div class="animation"></div>
<p>Inhale deeply for 4 seconds, hold for 4, exhale for 6.</p>
</div>
`;
document.body.appendChild(overlayElement);
// ... animate breathing exercise
}
} InterventionEngine periodiškai tikrina vartotojo veiklos ir įžvalgos duomenis prieš kiekvieną registruotą intervenciją shouldTrigger sąlyga. Kai suaktyvėja intervencija, variklis jį vadina render būdas parodyti vartotojui sutrikimą.
3. Įžvalgų sinchronizavimas
InsightsSync Modulis bendrauja su „Backend“ API, kad siųstų veiklos duomenis ir gautų ML sukurtas įžvalgas. Tam, kad būtų sumažintas tinklo pridėtinės išlaidos ir optimizuotas našumas, jis naudoja droselį, pakabintą metodą.
class InsightsSync {
private readonly SYNC_INTERVAL = 60_000; // 1 minute
private readonly BATCH_SIZE = 100;
private activityQueue: TabActivity() = ();
constructor(private readonly activityTracker: ActivityTracker) {
setInterval(this.syncInsights, this.SYNC_INTERVAL);
}
private async syncInsights() {
const batchedActivities = this.activityQueue.splice(0, this.BATCH_SIZE);
if (batchedActivities.length === 0) {
return;
}
try {
const insights = await fetch('/api/insights', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(batchedActivities),
}).then((res) => res.json());
// ... update intervention engine with new insights
} catch (err) {
console.error('Error syncing insights:', err);
this.activityQueue.unshift(...batchedActivities);
}
}
enqueueActivity(activity: TabActivity) {
this.activityQueue.push(activity);
}
} InsightsSync Modulis palaiko an activityQueue Norėdami saugoti veiklos duomenis ir periodiškai siunčiant duomenų partijas į „Backend“ API. Backendas grąžina ML sukurtų įžvalgų rinkinį, kuris vėliau naudojamas atnaujinti InterventionEnginesukelia logiką.
„Backend API“ ir „ML Pipeline“
„Clarity Pro Backend“ yra sukurta be serverio, įvykių paremtos architektūros, naudojant „AWS Lambda“, „API Gateway“ ir „DynamoDB“. Kai naršyklės plėtinys siunčia veiklos duomenų paketą, jis suaktyvina „Lambda“ funkciją, kuri apdoroja duomenis ir atnaujina vartotojo veiklos istoriją „DynamoDB“.
„Lambda“ funkcija taip pat skelbia veiklos duomenis į „Amazon Kinesis“ srautą, kuris patenka į realaus laiko ML vamzdyną. Vamzdynas, įgyvendintas naudojant „Amazon Sagemaker“, atlieka šiuos veiksmus:
- Duomenų išankstinis apdorojimas: Išvalo, normalizuojasi ir neapdorotos veiklos duomenis paverčia tokiu formatu, tinkamu mokyti ML modelius.
- Funkcijų inžinerija: Ištrauka svarbias funkcijas iš iš anksto apdorotų duomenų, tokių kaip įsitraukimo metrika, turinio kategorijos ir laikas pagrįsti modeliai.
- Modelio mokymas: Treniruoja ML modelių rinkinį, kad būtų galima numatyti konkrečias vartotojams skirtas įžvalgas, tokias kaip streso lygis, fokusavimo trukmė ir turinio nuostatos.
- Įžvalgų karta: Taikomi apmokyti modeliai naujausiems veiklos duomenims, kad būtų galima sugeneruoti kiekvieno vartotojo įžvalgas realiuoju laiku.
Tada sugeneruotos įžvalgos saugomos „DynamODB“ ir pateikiami naršyklės plėtiniui per /api/insights baigties taškas.
Čia pateiktas supaprastintas įžvalgų generavimo proceso pavyzdys, naudojant streso lygio numatymo modelį:
import boto3
import numpy as np
from sklearn.linear_model import LogisticRegression
def train_stress_model(user_data):
features = extract_features(user_data)
labels = user_data('stress_level')
model = LogisticRegression()
model.fit(features, labels)
return model
def predict_stress_level(model, activity_data):
features = extract_features((activity_data))
stress_level = model.predict_proba(features)(0)(1)
return stress_level
def lambda_handler(event, context):
user_id = event('user_id')
activity_data = event('activity_data')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('user_activity')
response = table.query(KeyConditionExpression=Key('user_id').eq(user_id))
user_data = response('Items')
stress_model = train_stress_model(user_data)
stress_level = predict_stress_level(stress_model, activity_data)
insights = {
'user_id': user_id,
'timestamp': activity_data('timestamp'),
'stress_level': stress_level,
# ... other insights
}
table.put_item(Item=insights)
return insightsŠiame pavyzdyje train_stress_model Funkcija moko logistinės regresijos modelį vartotojo istorinėje veiklos duomenyse, kad numatytų streso lygį. predict_stress_level Funkcija taiko apmokytą modelį naujausiems veiklos duomenims, kad būtų sukurta realaus laiko streso lygio įžvalga.
Našumo optimizavimas ir mastelio keitimas
Siekdama užtikrinti, kad „Clarity Pro“ išlieka veikianti ir keičiama augant vartotojų bazei, komanda įdiegė keletą optimizavimo metodų:
- Kliento pusės droselis: Naršyklės pratęsimas dreifuoja veiklos stebėjimo ir įžvalgų sinchronizavimo procesus, kad sumažintų CPU ir tinklo naudojimą.
- Be serverio architektūros: „Backend“ API ir ML vamzdynai yra sukurti ant „AWS Lambda“, kuri automatiškai padidėja atsižvelgiant į gaunamą užklausų tūrį.
- Duomenų padalijimas: „DynamoDB“ lenteles padalijamos vartotojo ID, kad būtų galima tolygiai paskirstyti skaitymo ir rašymo pralaidumą bei sumažinti karštus skaidinius.
- Talpyklos kaupimas: „Backend“ API talpyklose dažnai pasiekiamos įžvalgos, naudojant „Amazon Elasticache“, kad sumažintų latentinį ir duomenų bazės apkrovą.
- Papildomas mokymasis: „ML Pipeline“ naudoja laipsniškus mokymosi metodus, kad modelius atnaujintų realiuoju laiku, kai gaunami nauji veiklos duomenys, o ne perkvalifikuoti nuo nulio.
Štai pavyzdys, kaip laipsniškas mokymasis gali būti įgyvendinamas naudojant „Scikit-Learn“ partial_fit metodas:
def update_stress_model(model, activity_data, stress_level):
features = extract_features((activity_data))
model.partial_fit(features, (stress_level), classes=(0, 1))
return model
def lambda_handler(event, context):
# ... retrieve user data and train initial model
for activity_data in event('activity_data'):
stress_level = predict_stress_level(stress_model, activity_data)
stress_model = update_stress_model(stress_model, activity_data, stress_level)
# ... save updated model and generate insightsAtnaujindamas streso modelį su kiekvienu nauju veiklos duomenų tašku, ML vamzdynas gali prisitaikyti prie kintančio vartotojo elgesio realiuoju laiku be visiško perkvalifikavimo.
Testavimas ir diegimas
Norėdami išlaikyti aukštos kokybės kodų bazę ir sugauti potencialius problemas anksti, „Clarity Pro“ komanda įgyvendino išsamią testavimo strategiją:
- Vieneto testai: Vienetų bandymų rinkinys, naudojant „Jest“ ir „Mocha“, apima kiekvieną modulį ir komponentą naršyklės plėtinyje ir „Backend“ API.
- Integracijos testai: Integracijos bandymai nuo galo iki galo atliekami naudojant „Selenium“ ir „PloPeteer“, kad būtų užtikrintas naršyklės išplėtimas ir „Backend“ API kartu sklandžiai.
- Įkelkite testus: „Backend“ API ir ML dujotiekis yra atliekami apkrovos bandymams, naudojant tokius įrankius kaip artilerija ir skėris, kad patikrintų, ar jie gali tvarkyti numatomą srauto kiekį.
- A/B testai: Naujos funkcijos ir intervencijos yra perduodamos vartotojų pogrupiui A/B testavimo sistemoje, siekiant įvertinti jų poveikį įsitraukimo ir gerovės metrikai.
Komanda naudoja CI/CD dujotiekį, sukurtą pagal „GitHub“ veiksmus, norėdama automatiškai paleisti testus, kurti artefaktus ir diegti gamybos atnaujinimus. Dujotiekis suaktyvinamas kiekviename pastangoje į pagrindinę šaką ir seka mėlynai žalią diegimo modelį, kad būtų kuo mažiau prastovos ir prireikus įgalina greitą atšaukimą.
Išvada
„Clarity Pro“ yra naujas požiūris į skaitmeninės gerovės skatinimą pasinaudojant elgesio psichologijos principais ir ML skatinamu personalizavimu. Naršyklės pratęsimas įgalina vartotojus kurti labiau sąmoningus skaitmeninius įpročius, nesiimant ribojančių blokavimo ar laiko apribojimų, pateikiant švelnias, kontekstines intervencijas tinkamomis akimirkomis.
„Clarity Pro“ techninė architektūra, daugiausia dėmesio skiriant skaičiavimui be serverių, realaus laiko ML vamzdynų ir kliento našumo optimizavimo, demonstruojama geriausia keičiamo mastelio, duomenų pagrįstų programų kūrimo praktika. Kaip pabrėžė renginio techniniai vertintojai, įskaitant Nisargą Shahą, efektyvus projekto atminties valdymas ir moduliniai projektavimo modeliai prisideda prie jo bendro patikimumo ir palaikymo.
Žvelgiant į ateitį, „Clarity Pro“ komanda planuoja išplėsti galimų intervencijų spektrą, ištirti sudėtingesnius ML personalizavimo metodus ir potencialiai integruoti su kitomis skaitmeninėmis gerovės įrankiais ir platformomis. Atviro pasiūlymo pagrindinius kodų bazės komponentus ir pasidalindami savo mokymosi su platesne kūrėjų bendruomene, jie tikisi įkvėpti tolesnes inovacijas mąstymo technologijos srityje.






